From Model Primitives to Production AI Systems
How modeling assumptions, system constraints, and feedback loops shape effective AI solutions from a practitioner’s perspective
Date: January 01, 2026 | Author: Yongjun Chen
We are at a stage where the benefits of AI are widely visible.
AI progress is often framed around models: larger architectures, better objectives, and stronger benchmarks. Yet many of the most consequential challenges in practice arise outside the model itself. Assumptions made during training quietly break during inference; systems optimized for offline metrics behave unpredictably under real workloads; and AI product success depends on asymmetric feedback signals that models were never designed to observe.
Products enable iterative learning through deployment, while great products and research strengthen each other. Products keep us grounded in reality and guide us to solve the most impactful problems. —- Thinking Machines Lab
This post reflects on what it takes to move from models to products, viewing models, systems, and user-facing features as equally important components of the same pipeline. Using a small set of examples to illustrate how assumptions, constraints, and failure modes surface at different points in this pipeline, and how system-level constraints shape real features.
Model Primitives
Data mixtures, computation infrastructure, and training algorithms form the core foundations of strong AI models.
Data Determinism
Data quality is widely recognized as a dominant factor in model performance, driving extensive effort in cleaning, labeling, sampling, and synthesis. A less discussed but equally foundational element is data determinism.
As models scale and training pipelines grow more complex, data stops being a static input. It is continuously generated, filtered, mixed, and reshaped across ETL jobs, online sampling logic, distributed training, and iterative retraining. In this setting, small sources of nondeterminism quietly accumulate, making training runs difficult to reproduce. The problem becomes especially acute when data mixtures are constructed online rather than frozen offline.
Importantly, this nondeterminism rarely comes from obvious bugs. It often emerges from reasonable design choices: stochastic decoding during data synthesis, online mixing that depends on worker order or runtime state, or curriculum changes without a stable notion of what data the model has already seen. Modern frameworks do provide strong controls for randomness inside model execution, JAX, for example, exposes explicit PRNG keys that scale cleanly across devices, while PyTorch relies on global and worker-level seeds.But these mechanisms operate at a different layer. Once randomness enters through data generation or distributed input pipelines, purely stateful control becomes increasingly hard to reason about or replay at system scale.
The goal is not to eliminate randomness, but to make it reproducible. This means treating data sampling as a pure, stateless function of explicit inputs, such as seeds, global steps, and configuration, rather than as an emergent property of mutable pipeline state. Randomness should be derived from explicit coordinates; data sources, preprocessing steps, and mixture weights should be versioned and auditable; and curriculum changes should be intentional and traceable. For streaming or continual learning, reproducibility shifts from exact replay to controlled, well documented evolution.
Computation Infrastructure
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. —- Richard Sutton
As many pioneers have emphasized, computation is not just a resource but also a design constraint.
Choices around hardware, parallelism strategies, and system architecture determine what is possible downstream. Once set, changing them becomes expensive or infeasible. Parallelism decisions determine: whether training runs can be debugged and reasoned about; how compute scales across training and inference; whether rollouts, evaluation pipelines, and reinforcement learning loops remain tractable.
At scale, computation infrastructure defines the shape of the system long before it defines its speed.
Parallelism Starts from Communication
Conceptually, any parallel system can be decomposed into three atoms:
- Devices: independent compute units (CPU cores, GPUs, TPU cores)
- Channels: point-to-point communication paths between devices
- Communicators: semantic layers that define collective operations (e.g., all-reduce, all-gather, scatter)
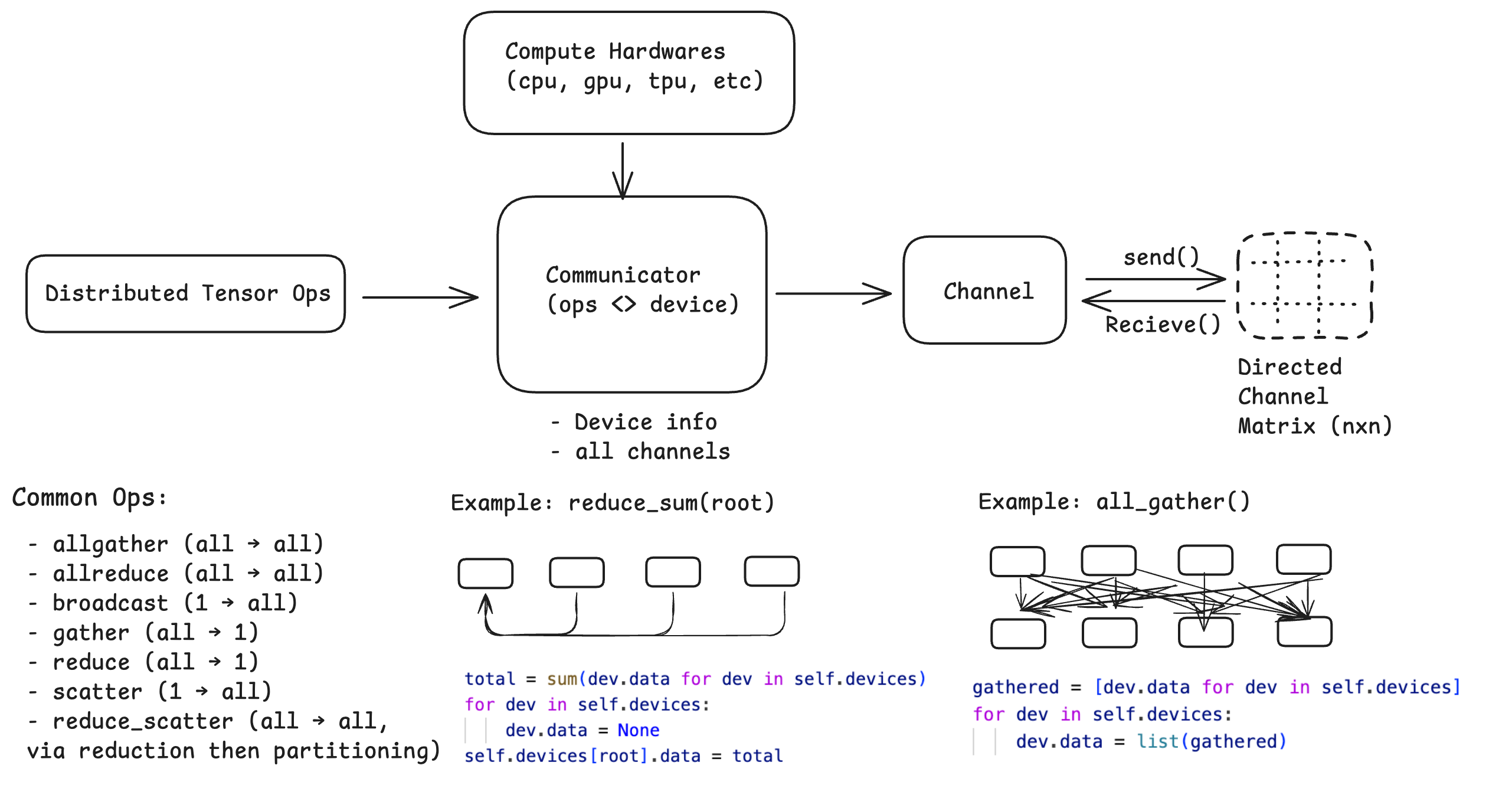
A minimal atom relationships is illustrated in above figure.
From Communication Atoms to Parallelism Strategies
Once these abstractions are in place, parallelism strategies (such as DDP, FSDP, TP, Pipeline Parallelism, Export Parallelism, and hybrid solutions) naturally occupy the layer above. Many excellent resources document options and trade-offs in depth. (e.g., Weng, 2021 and Stanford CS336). At this level, parallelism is no longer a collection of tricks. It is a structured mapping from tensors to devices, with communication patterns determined by that mapping. While strategies can become arbitrarily complex, starting from simpler designs tends to make scaling smoother.
Training Architecture
While computation infrastructure defines the shape of a system, training architecture determines how that shape evolves. Seemingly local architectural choices often have systemic consequences, governing parameter movement, stability, and their interaction with infrastructure constraints. Over time, a few design patterns repeatedly become standard choices.
Low-Rank Adaptation (LoRA): Tuning a base model is often costly and difficult to scale when serving many clients. LoRA introduces trainable low-rank adapters alongside frozen base parameters (Hu et al. 2021). Rather than a shortcut to full fine-tuning, LoRA functions as an auxiliary structure attached to the model. Viewed this way, LoRA restricts learning to a small set of adapter parameters, keeping changes localized and the base model stable (e.g., LoRA as programs). This framing becomes increasingly important as models are reused, composed, and adapted across tasks and products.
Memory-Aware Attention: Out-of-memory (OOM) issues are often the first constraint encountered when running AI models. FlashAttention (Dao et al. 2022) and its successors (v2, v3) are frequently framed as performance optimizations. Their deeper impact is architectural. Online softmax computation, originally motivated by numerical stability, combined with careful tiling and backward recomputation, reshapes the memory–compute trade-off. These techniques together enable attention patterns and context lengths that were previously infeasible under conventional memory layouts.
Mixture of Experts: As Transformer models scale, most computation becomes dominated by feed-forward networks (FFNs), which motivated Mixture-of-Experts (MoE) as a way to scale capacity without paying the full dense compute cost. MoE architectures (Du et al. 2021, Zoph et al. 2022) are attractive primarily for scaling: by activating only a subset of experts per token, they allow model capacity to grow while keeping per-token compute roughly constant. At system level, however, MoE is less a local modeling trick than a system-level choice, routing, load balancing, and expert utilization tightly couple data, optimization, and infrastructure behavior. Imbalances formed during training often surface later as unstable rollouts, poor utilization, or degraded reinforcement learning performance, making MoE success depend on careful co-design across data, model, and infrastructure rather than architecture alone.
From Models to Systems
Concrete lenses for examining how models fail as systems include inference constraints, agentic interactions, learning dynamics, and numerical stability.
Inference Optimization
In autoregressive generation, attention is often the first place where inference hits real limits. While KV caching reduces decoding complexity from quadratic to linear in sequence length, naive KV allocation quickly runs into memory fragmentation and poor utilization under high concurrency. PagedAttention addresses this by managing KV cache as a virtualized memory system, decoupling logical sequence length from physical memory layout and enabling efficient sharing and eviction across requests. This abstraction underpins vLLM, which treats inference not as isolated forward passes, but as a continuous scheduling problem over many concurrent sequences, optimizing both throughput and time-to-first-token (TTFT). In longer-lived agentic sessions, KV reuse is often extended into a hierarchical cache, sometimes backed by a distributed KV store (Redis Attention), to avoid repeated prefilling across turns.
Beyond memory, decoding itself becomes a systems problem. Speculative decoding (Chen et al. 2023, Leviathan et al. 2023) reduces end-to-end latency by letting cheap draft models propose multiple tokens that expensive target models verify in parallel, without changing output distributions. Systems such as DeepSeek V3 use multi-token prediction to produce stronger drafts for speculative decoding, while newer variants move toward speculative editing (e.g., EfficientEdit), where only edited spans are regenerated and unchanged context is reused. At the extreme, even an n-gram model can serve as the draft, reducing the cost of validating local edits rather than regenerating the full sequence.
Agentic Systems
While inference focuses on generating a response for a single request, agentic models extend model behavior across steps and interactions. With the emergence of Scratchpad and Chain-of-Thought, language models began to exhibit explicit reasoning behavior rather than acting as purely passive sequence predictors. The ReAct (Reasoning and Acting) was one of the early works to formalize this shift by interleaving reasoning traces with action decisions, allowing models to reason and act in a loop instead of producing a single text continuation.
This marked a paradigm shift in how models are used. Rather than simply responding to prompts, models began deciding what to do next, invoking tools, calling APIs, and interacting with environments. In agentic settings, a model becomes an autonomous component that reasons, plans, and acts across multiple steps with persistent state and feedback loops. This introduces tight integration with external tools, memory across interactions, and long-horizon decision making, which enable real-world automation but also introduce challenges in reliability, controllability, and behavioral stability.
Reinforcement Learning for Agents
In agentic settings, supervised learning and preference modeling quickly reach their limits: feedback is delayed, data is sparse, and good behavior depends on long-horizon trade-offs rather than local likelihood. Once models act and interact with an environment, learning signals become outcomes of decision sequences over time, making reinforcement learning the minimal framework for aligning agentic behavior.
At its core, REINFORCE provides the policy-gradient foundation by linking actions to delayed rewards through sampled trajectories. As systems scale, purely on-policy learning becomes impractical, and importance sampling, typically with respect to a reference or behavior policy, enables reuse of experience while correcting for distribution mismatch. Building on these foundations, policy optimization methods for agentic LLMs primarily differ in how they constrain policy updates and normalize learning signals at scale. PPO stabilizes training by explicitly restricting policy movement through ratio clipping or KL penalties relative to a reference policy, together with a learned value function for variance reduction, but remains sensitive to absolute reward scale and reward-model drift; DPO removes explicit environment interaction and value estimation by optimizing directly against preference comparisons under a fixed reference, trading adaptability for simplicity when feedback is static; and GRPO, in contrast, eliminates the value function and replaces absolute rewards with within-group relative comparisons, making updates less sensitive to reward magnitude and prompt-dependent variance, particularly effective in multi-sample, reasoning-heavy settings where only comparative signals are reliable. Following the success of DeepSeek-R1, which validated GRPO-style optimization at scale, a growing body of follow-up work has built on the same core idea (Liu et al. 2025, Zheng et al. 2025).
In fully agentic settings, with environment interaction and long-horizon feedback, these control issues become at least as important as innovations in reinforcement learning algorithms. Recent work such as rStar2-Agent makes this explicit. From an engineering perspective, reinforcement learning for agentic LLMs is best understood as a set of tools for managing variance, normalization, and forgetting, rather than as a single unified algorithm. The rapid maturation of this direction is further reflected in a recent survey by Zhang et al. 2025, which reviews over five hundred works on agentic reinforcement learning for LLMs.
Numerical Stability
Numerical instability in large-scale AI systems often arises from a small set of high-frequency numerical operators whose numerical behavior degrades under low precision, approximation, and scale. These issues typically accumulate quietly and later surface as hard-to-diagnose regressions.
One particularly common source is exponentiation over log-space quantities, which appears throughout modern systems in softmax, attention, and probabilistic objectives. Softmax is therefore computed in its numerically stable form as:
Standard safeguards such as logit shifting and numerically stable softmax implementations are therefore not optimizations, but baseline requirements for reliable systems. Related guardrails, such as z-loss, are often introduced to explicitly penalize unbounded logit growth, an effect that becomes especially important in high-entropy regimes and in MoE models, where unstable logits can directly destabilize routing decisions.
Closely related failures arise when logarithms, ratios, and exponentiation interact under low precision arithmetic. As probabilities approach zero, operations like $\log(p)$ become unstable; when combined with exponentiation, as in ratio-based objectives such as PPO, small numerical errors can be amplified into biased gradients or silent metric drift. In these settings, stability depends less on heuristics like clipping and more on controlling how log-probabilities enter the exponential regime.
Precision choice further shapes how these effects manifest. BF16 has become the de facto choice for large-scale training due to its wider exponent range, but frequent switching between training and rollout phases can introduce rounding-induced nondeterminism (He et al. 2025). While FP16 can reduce rounding noise (Qi et al. 2025), it interacts poorly with exponentiation-heavy approximations (Schulman 2020) (e.g., FP16 with K3-style KL estimation), which are commonly used in alignment and reinforcement learning. For large-scale training, no single precision format is universally safe. Stability emerges from how precision, approximation, and objectives interact.
From Systems to Products
Distillation
In reality, not everyone, or every product can afford a frontier-scale model. Cost, latency, reliability, and privacy constraints often make large models impractical to serve directly. Distillation offers a practical way forward: keep the behavior we care about, while running a much smaller, cheaper, and more predictable model in production.
Knowledge distillation aligns the student’s output distribution with that of the teacher, most commonly through a KL-divergence objective. Note that the direction of KL matters in generative models (Eric’s post, Gu et al. 2025). Minimizing $KL(p||q)$ (forward KL) encourages mode-covering behavior, pushing student to match all modes of the teacher distribution. In contrast, minimizing $KL(q||p)$ (reverse KL) is mode-seeking, concentrating probability mass on the teacher’s most likely outputs. In deployment settings, the reverse KL often produces sharper and more decisive student behavior, which is desirable when distillation targets a production model rather than a generative oracle.
Most traditional distillation pipelines are off-policy, relying on static datasets or trajectories generated by earlier teacher checkpoints. As the student evolves, this can introduce distribution mismatch and gradual forgetting. On-Policy Distillation (Gu et al. 2025) trains the student on its own rollouts, with supervision provided by the teacher, keeping the learning distribution aligned and avoiding stale supervision.
Distillation remains one of the most practical ways to turn frontier models into widely usable systems. However, effective distillation is rarely a purely algorithmic choice. It depends on system level decisions: how teachers are selected, how trajectories are generated, how frequently policies are refreshed, and how losses interact with serving constraints.
Building AI Features
When training models, we optimize deterministic signals such as loss, reward, and accuracy. When building features, we confront non-deterministic user experience, observed only through imperfect proxies like usefulness, trust, and friction. In training, failure is reversible; in production, a single visible failure can permanently erode trust. Managing this asymmetry is one of the core challenges of building AI features and require substantial post-training effort to align what models optimize with how people actually experience and judge a product.
Beyond the model itself, effective features rely on good context engineering and tool management. Models do not inherently know what matters; context must be selected, structured, and constrained. Tool use adds risk: deciding when to act, which tools to access, and how to handle failures often determines visible reliability. Most failures arise from poorly scoped context or brittle orchestration, not model quality.
AI features are also shaped by human-facing constraints. UI design determines how uncertainty and errors are perceived, while system constraints such as latency, token limits, and input/output modalities bound what interactions are feasible. For products meant to benefit broad audiences, additional constraints emerge: language coverage, cultural norms, accessibility, and regional expectations. Users interact with behavior, not loss functions. Feature design therefore prioritizes predictability, graceful degradation, and avoiding surprising failures over marginal gains in average model quality.
Evaluation and risk therefore look fundamentally different at the feature level. Metrics like latency, cost, task success are quantifiable, but the most important signals are subjective: Is this helpful? Is it annoying? Does this feel like my style? Offline benchmarks rarely capture these dimensions. Unlike models, features are judged continuously in real use, and trust, once lost, is difficult to recover.
Even when AI products increasingly serve other entities, the core challenge remains: models optimize objectives, but products depend on stable interfaces and adaptive behavior shaped by subtle, implicit feedback. Whether the user is a person or another system, successful AI features treat models, systems, and user-facing design as equally important components of the same pipeline.